shonDy ist eine dreidimensionale multiphysikalische numerische Simulationssoftware, die auf der gitterfreien Partikelmethode basiert. Diese Software eliminiert die durch komplexe Gitter auferlegten Einschränkungen während der Simulation, indem Fluideigenschaften auf Partikeln gespeichert werden. Traditionelle Gitterinteraktionen werden in Partikel-Partikel-Interaktionen umgewandelt. Diese Interaktionen haben einen definierten Einflussbereich, der als Einflussradius bezeichnet wird. Eine Kugel mit dem Mittelpunkt an einem Partikel und dem Radius r wird definiert, Partikel innerhalb dieser Kugel werden als Nachbarn betrachtet.
Zur Verdeutlichung wird der zweidimensionale Fall unten dargestellt:
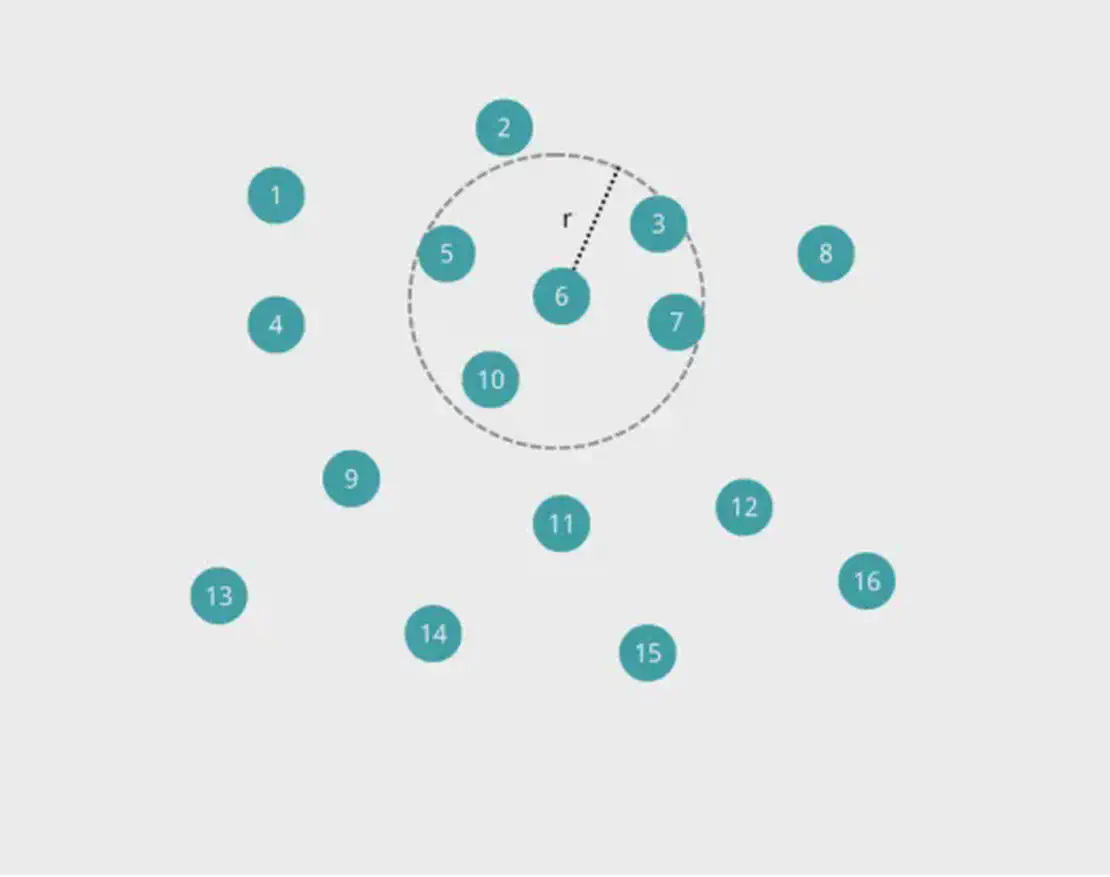
Abbildung 1: Beispiel für Nachbarpartikel im 2D-Fall
Am Beispiel von Partikel 6 haben seine Nachbarpartikel die IDs 3, 5, 7 und 10.
Problemanalyse
Um Partikelinteraktionen zu berechnen, müssen wir zunächst die Nachbarn jedes Partikels bestimmen. Bei n Partikeln würde ein Brute-Force-Durchlauf-Ansatz eine Zeitkomplexität von O(n²) erfordern. In großen Projekten kann die Anzahl der Partikel Millionen oder sogar Dutzende von Millionen erreichen, was diese Rechenzeit inakzeptabel macht. Angesichts der inhärent hohen Zeitkomplexität dieses Algorithmus bietet eine darauf basierende Paralleloptimierung nur begrenzten Nutzen. Daher ist ein effizienterer Ansatz erforderlich.
Der Kern des Problems besteht darin, dass jedes Partikel alle anderen Partikel durchlaufen muss, um seine Nachbarn zu finden, obwohl die überwiegende Mehrheit dieser Durchläufe unnötig ist. Daher können wir die Zeitkomplexität reduzieren, indem wir die Anzahl der Partikel minimieren, die jedes Partikel durchlaufen muss, um seine Nachbarn zu finden. Die Parallelisierung basiert dann auf diesem optimierten Algorithmus.
Spezifische Implementierung
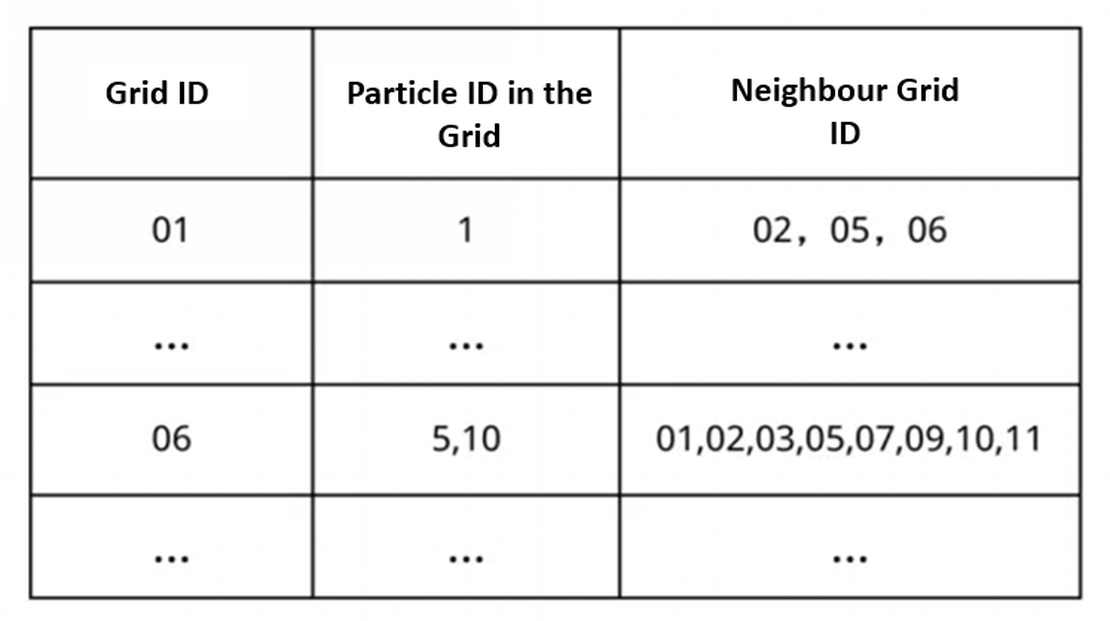
Wir bilden jedes Partikel im 3D-Raum auf ein 3D-Gitter ab, indem wir es auf das Gitter zeichnen. Dies wandelt die Partikel-zu-Partikel-Positionsbeziehungen in Gitterzelle-zu-Gitterzelle-Beziehungen um. Der Partikeldurchlauf wird somit in einen Gitterdurchlauf umgewandelt.
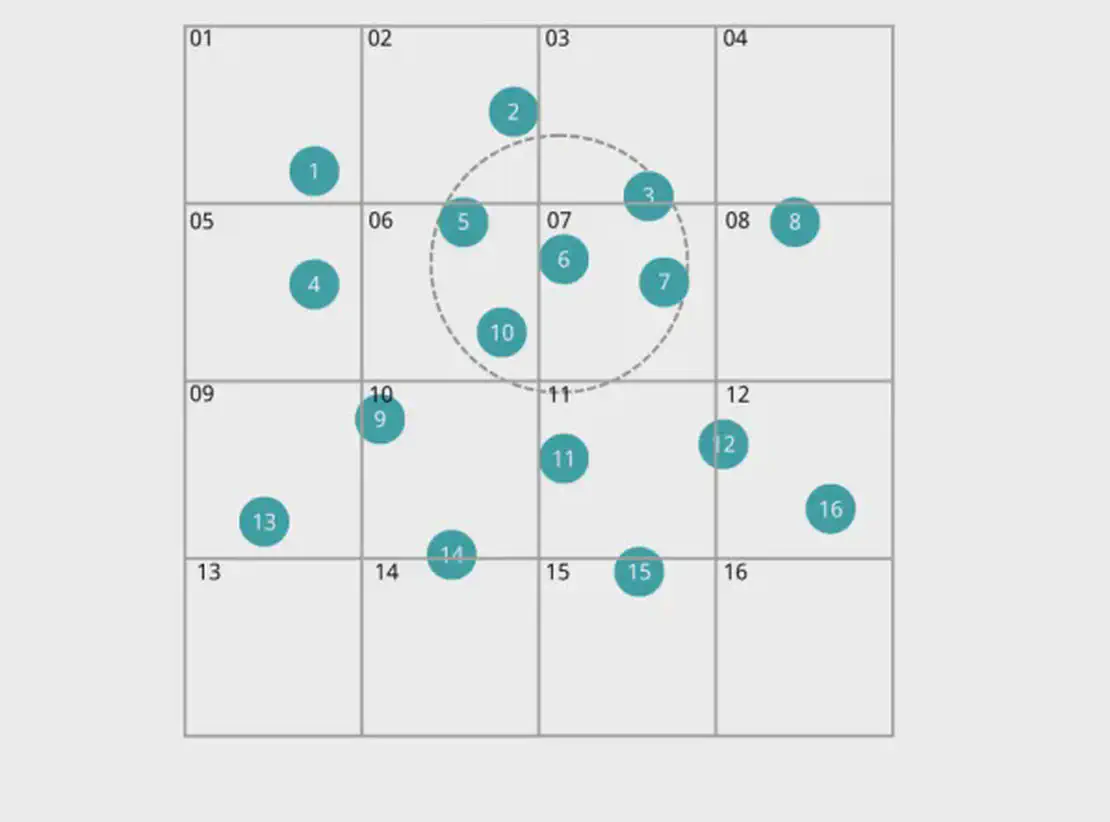
Abbildung 2: Abbildung von Partikeln auf Gitterzellen
Wie in der Abbildung dargestellt, entspricht jede Partikel-ID der Gitter-ID, die sie belegt.
Aus Effizienzgründen wird die Gitter-Seitenlänge typischerweise gleich dem Einflussradius des Partikels gesetzt. Bei der Berechnung der Nachbarn eines Partikels genügt es, den Abstand zwischen dem Zielpartikel und jeder der 26 umgebenden Gitterzellen zu berechnen und dann jeden Abstand mit dem Einflussradius zu vergleichen, um alle benachbarten Partikel zu identifizieren.
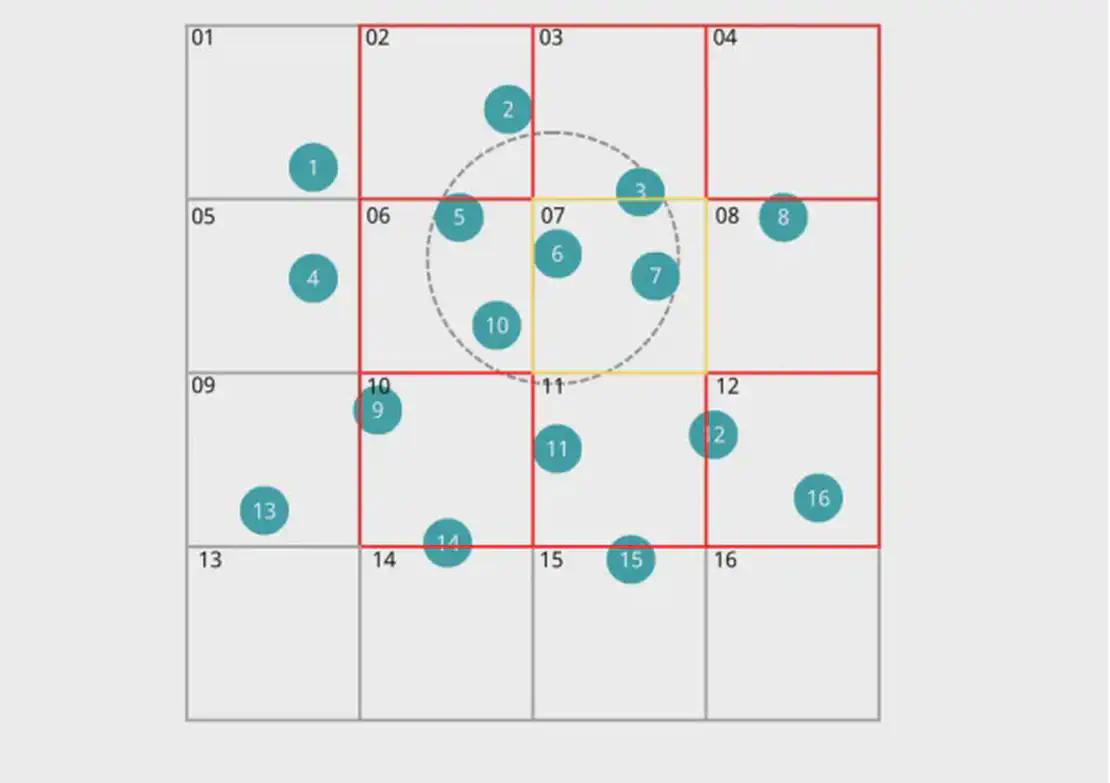
Abbildung 3: Aktive Zellen für Partikelabbildung
Bei der Suche nach benachbarten Partikeln von Partikel Nummer 6 genügt es, nur unter Partikeln in den Gitterzellen zu suchen, die Gitterzelle 07 umgeben. Dies reduziert den Suchbereich erheblich und senkt dadurch die Zeitkomplexität.
Einführung in gängige Parallelmethoden
1. Datenparallelität
Dieser Ansatz umfasst im Wesentlichen die Aufteilung von Daten innerhalb eines Programms und deren Verteilung auf verschiedene Recheneinheiten zur Verarbeitung. Die Daten können sowohl Eingaben als auch Ausgaben umfassen. Bei der Datenaufteilung sind die folgenden drei Überlegungen wesentlich:
Lastverteilung: Das Datenvolumen und die Rechenlast, die von jeder Recheneinheit verarbeitet werden, sollten ungefähr gleich sein. Andernfalls könnten einige Einheiten untätig bleiben, was zu verschwendeten Rechenressourcen führt.
Informationsaustausch: Speicherkonfigurationen im Parallelrechnen fallen im Allgemeinen in zwei Kategorien – gemeinsamer Speicher und verteilter Speicher. Gemeinsamer Speicher wird typischerweise in Mehrkernprozessoren verwendet, bei denen mehrere Verarbeitungseinheiten denselben Speicherplatz teilen, was Maßnahmen zur Verhinderung von Speicherkonflikten erfordert. Verteilter Speicher wird häufig in Systemen verwendet, die aus mehreren Prozessoren bestehen, wobei jeder Prozessor seinen eigenen Speicherplatz hat und während der Berechnung Kommunikation erfordert.
2. Aufgabenparallelität
Dieser Ansatz beinhaltet die Aufteilung des Problems in Aufgaben und deren Zuweisung an verschiedene Prozessoren. Aufgaben müssen gegenseitig unabhängig sein, ohne Abhängigkeiten oder mit auflösbaren Abhängigkeiten.
Parallelisierung der Nachbarpartikelsuche
Wir lösen dieses Problem mit einem datenparallelen Ansatz. (Zur Verdeutlichung verwenden die folgenden Beispiele zwei Prozesse: Prozess 0 und Prozess 1)
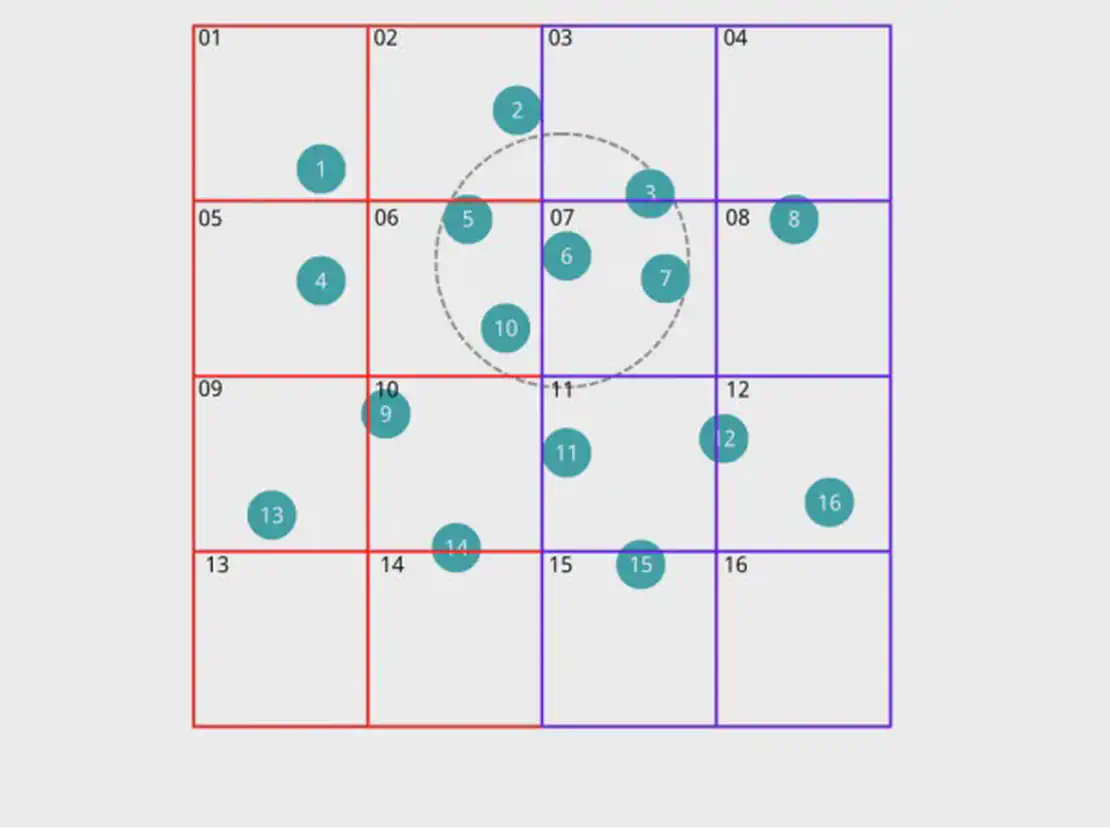
Gleichmäßige Verteilung der Partikel auf verschiedene Prozesse Parallele PartikelverteilungDer rote Bereich links wird Prozess 0 zugewiesen, und der violette Bereich rechts wird Prozess 1 zugewiesen.
Berechnung der Gitter-ID für jedes Partikel und Zuordnung der Partikel-ID zur Gitter-ID.Partikel-Gitter-IDs
Partikelinformationsübertragung in Grenzgittern: Einige Gitterzellen liegen an der Grenze zwischen zwei Prozessen, wie z. B. Gitter 06. Beim Auffinden benachbarter Partikel können Partikel in den Gittern 03, 07 und 11 auch Nachbarn von Partikeln in Gitter 06 sein. Aufgrund des verteilten Speicherzugriffsmodells fehlen Prozess 0 (der Gitter 06 hostet) Informationen über seine benachbarten Gitter und Partikel, was eine Kommunikation mit Prozess 1 erforderlich macht. Dasselbe gilt für die Grenzgitter von Prozess 1.
Iteration durch jedes Gitter im aktuellen Prozess, um seine benachbarten Gitter zu erhalten und dadurch Partikelinformationen von diesen benachbarten Gittern abzurufen. Sukzessive Berechnung des Abstands zwischen Partikeln in diesem Gitter und Partikeln in benachbarten Gittern. Dieser Prozess umfasst umfangreiche Berechnungen mit identischen logischen Operationen zwischen Partikeln und ohne Informationsaustausch, was ihn zu einem idealen Kandidaten für Parallelverarbeitung macht.
Ermittlung der ID der benachbarten Partikel jedes Partikels.
Erweiterungen
GPU-Beschleunigung Aktuelle Mainstream-GPUs verfügen über beträchtliche Rechenleistung, wobei Leistungsengpässe hauptsächlich bei Datenlese-/Schreibvorgängen auftreten. Um eine hohe Leistung zu erreichen, konzentrieren Sie sich darauf, ob die Datenstrukturen des Programms mit GPU-Eigenschaften übereinstimmen, wobei typischerweise zusammenhängender Speicher verwendet wird. Minimieren Sie außerdem häufige Lese-/Schreibvorgänge auf den globalen Speicher während der Programmgestaltung.
Hilbert-Kurven-Abbildung Dieser Algorithmus verwendet die Hilbert-Kurve, um ein dreidimensionales Gitter in eine eindimensionale ID abzubilden.
Definition in zwei Dimensionen: Die Hilbert-Kurve ist eine kontinuierliche parametrische Kurve. Durch Auswahl einer geeigneten Funktion wird eine kontinuierliche parametrische Kurve gezeichnet. Wenn der Parameter t Werte im Intervall [0, 1] annimmt, durchläuft die Kurve jeden Punkt innerhalb des Einheitsquadrats, was zu einer Kurve führt, die den gesamten Raum ausfüllt. Die Hilbert-Kurve ist stetig, aber nicht differenzierbar.Zweidimensionale Hilbert-Kurven-Darstellung
Im Kern ist es eine Form der Dimensionsreduktion – eine Kurve, die einen zweidimensionalen Raum in einen eindimensionalen Raum transformiert und ihn von zwei auf drei Dimensionen erweitert.
Dreidimensionale Hilbert-Kurven-Darstellung
Wir sind bereit zu helfen!
Füllen Sie das Formular aus
Geben Sie Ihre Kontaktdaten und Nachricht an.
Wir werden Sie kontaktieren
Wir vereinbaren eine kostenlose Beratung, um Ihre Ziele zu besprechen.
Maßgeschneidertes Angebot
Sie erhalten ein detailliertes Angebot mit Zeitplan, Leistungen und Preisen.
Projektstart
Nach der Genehmigung erhalten Sie direkten Zugang zu unseren Ingenieuren.
So erhalten Sie unsere Testversion:
Füllen Sie das Formular aus
Wählen Sie die Produkte aus, die Sie testen möchten, und füllen Sie das Formular aus.
Wir werden Sie kontaktieren
Unser Team wird sich mit Installations- und Aktivierungsdetails bei Ihnen melden.
Testen Sie unser Produkt
Nach Überprüfung des Produkts werden wir eine passende Lizenz für Sie finden.
Request received
Thanks! We’ll get back within 24 hours.
Vielen Dank für Ihre Kontaktaufnahme
Wir werden uns in Kürze melden
Wir verwenden Cookies, um Inhalte und Anzeigen zu personalisieren, Funktionen für soziale Medien bereitzustellen und den Website-Verkehr zu analysieren. Wir können diese Daten wie in unserer Cookie-Richtlinie beschrieben mit unseren Partnern teilen. Sie können Ihre Cookie-Einstellungen jederzeit auf unserer Cookie-Richtlinien-Seite ändern.
Cookie-Richtlinie